

DEEP DIVE: Election Betting vs 538
DEEP DIVE: Election Betting vs 538
ElectionBettingOdds.com and 538 are nearly TIED in their track records

Note: I created ElectionBettingOdds.com in 2015, where I aggregate betting markets’ predictions about elections. In this post, I tried hard to stay unbiased, even though I’m comparing my site’s track record with that of Nate Silver’s at FiveThirtyEight.com.
1. Who cares about predicting the future?
Lots of people, going back to the dawn of history.
In a history museum, I was struck by how many ancient writing tablets dealt with prediction. Here are some:

The items pictured show that the ancient Assyrians predicted important events — such as whether someone would go to war with them — by consulting the sky, earth, and sheep’s lungs.
The ancient Greeks, famously, had their oracles.
And all over the world, from the Aztec empire to China, people looked at the stars to make predictions.
But it’s safe to say that none of those forecasters put specific percentages on their forecasts — which would have helped them check their accuracy scientifically.
The scientific revolution, since roughly the early 1600s, has continuously created better prediction tools, using statistics and the scientific method.
Nate Silver’s site FiveThirtyEight.com does a good job with that approach to election predictions. Silver, who once made his money playing online poker, takes statistical modeling seriously, and transparently keeps an eye on his site’s prediction track record. His predictions are the “gold standard” of election modeling.
But another powerful technology of the modern world is markets. Also starting around the 1600s, we’ve seen incredible material success from using stock markets to allocate resources.
What if the power of markets could be harnessed for not just the economy — but for predictions, too?
That’s the idea behind prediction markets (also known as “betting markets” or just “betting.”) They work just like stock markets, except that instead of trading shares of stocks, you trade “shares” that pay out only if a certain event happens (such as a candidate winning an election.)
My site, ElectionBettingOdds.com, has now tracked 805 different candidate chances on prediction markets. The elections were between 2016-2022, and I averaged together several different markets from around the world — for US state-level races, relying mostly on the US exchange PredictIt.
So what do the data show? What modern forecasting method has the best record?
Bettors are very accurate election predictors
Let’s start with the bettors’ track record.
Remember that when bettors give a candidate, say, a 75% chance to win -- that means the candidate should win in just 75% of cases, and should lose 25% of the time. That ideal is shown by the white line, below.
The blue line shows how often bettors' predictions actually came to pass. Where the blue line differs from the white line, the predictions were imperfect:
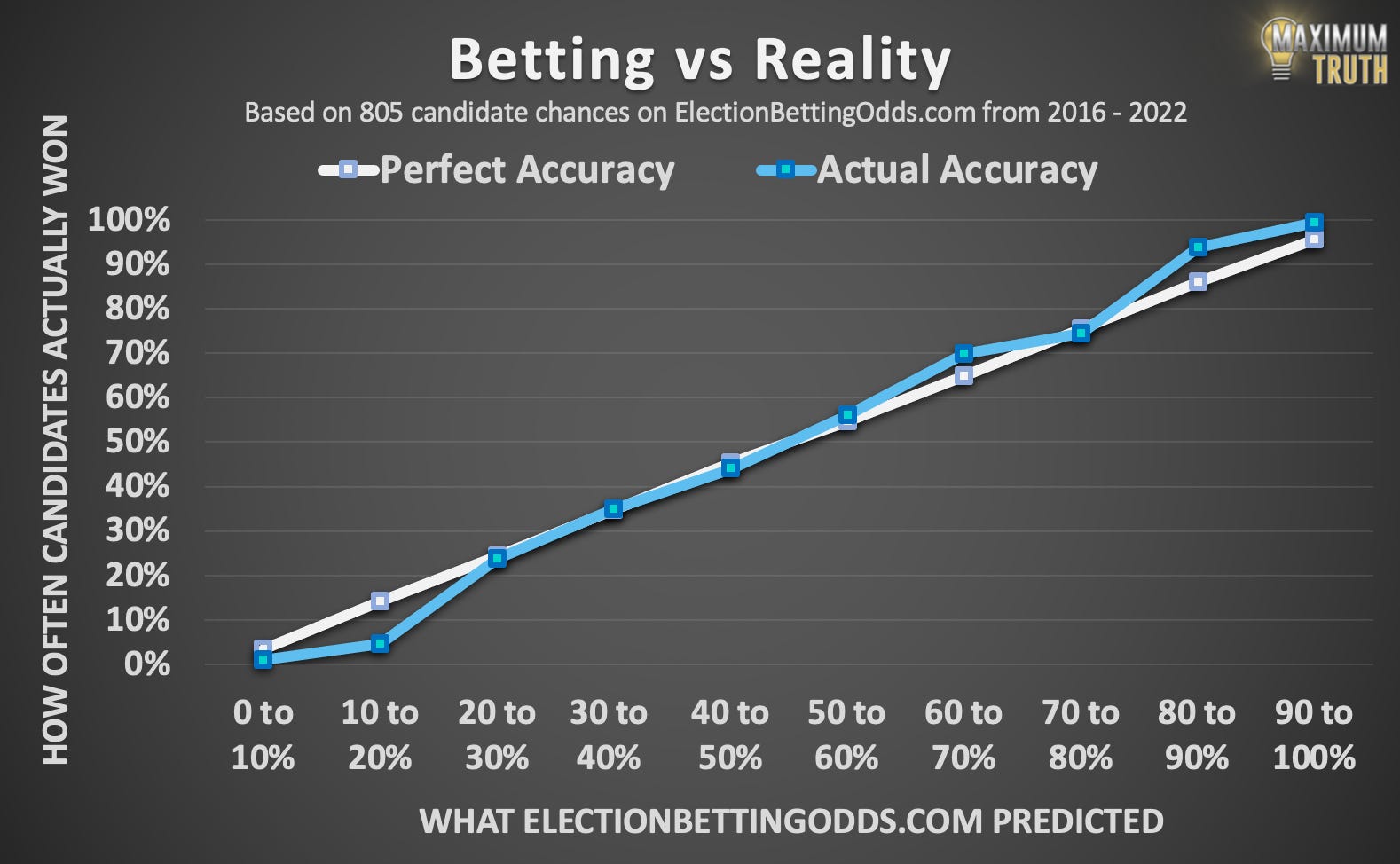
The chart shows that bettors have been very accurate.
For example, out of all candidates who were given between a 70 and 80% chance of winning at 8am on election days, 74.5% of them actually won.
There is one notable exception to bettors’ accuracy, however, which is visible in the graph: “underdog bias.”
For example, for candidates in the 10% to 20% range, bettors gave an average prediction of a 14% chance. Yet, across 66 candidates given odds in that range, only 3 of them (4.5%) actually ended up winning.
That flaw is also mirrored1 on the higher end of the graph — bettors are insufficiently confident of shoe-in candidates.
Why don’t smart traders see the “underdog bias” and make money by trading against the underdog bettors? One reason is regulatory: PredictIt, for example, limits traders to $850 per race, which prevents “smart money” from fully correcting things.
A second reason involves opportunity cost, which can cause underdog bias on less-regulated markets, too. Basically, if you were to bet against a 1% underdog for the 2024 election, you’d have to put up $99 to make just $1. That roughly 0.5% annual return on investment wouldn’t be so great, even if the true odds were 0.
The underdog bias isn’t the end of the world — bettors still give the public a general impression of the race — “so-and-so is really likely to win” — and they almost always do win. But the bettors’ precision is lacking there.
However, in the mid-range of 20% to 80%, which is where the most heated speculation usually lies, bettors have been extremely accurate — not far from perfectly calibrated, even.
Bettors beat typical election models and “experts”
The track record of many election modeling “experts” is embarrassing, and most of them quit trying after some epic failures.
The most epic was that of the Princeton Election Consortium, which gave Trump a “less than 1%” chance of winning the 2016 election on election morning.
By contrast, ElectionBettingOdds.com gave Trump a more reasonable 20.2% chance on election morning, higher than the odds given by any statistical model — except for Nate Silver’s FiveThirtyEight.com, which gave Trump a 28% chance. (See here for all the models’ predictions on election morning.)
Most statistical modelers quit the business after 2016, and the head of the Princeton Election Consortium stopped giving percentages on his site.
A working paper by Dhruv Madeka concluded that in 2016, electionbettingodds.com beat all prediction models, except for Nate Silver's polls-plus model, which it was tied with.
Silver’s site, and the betting, are the only two things I know of with comparably thorough and long track records.
So the following analysis will compare the bettors to FiveThirtyEight’s top-notch modeling, rather than the whole field of failed models and “experts” over the years, against which the market clearly wins.
NEARLY TIED: Bettors vs FiveThirtyEight.com
I finally spent a week painstakingly matching up the races tracked on ElectionBettingOdds.com and FiveThirtyEight.com, and there are 687 candidate chances that both sites tracked between 2016 and 2022.
If a race was forecast by one site but not the other, it was excluded, in order to have an apples-to-apples comparison. The rest of this article uses this dataset.
Here’s what the track record for the sample of the 687 remaining candidate chances looks like, on each site:
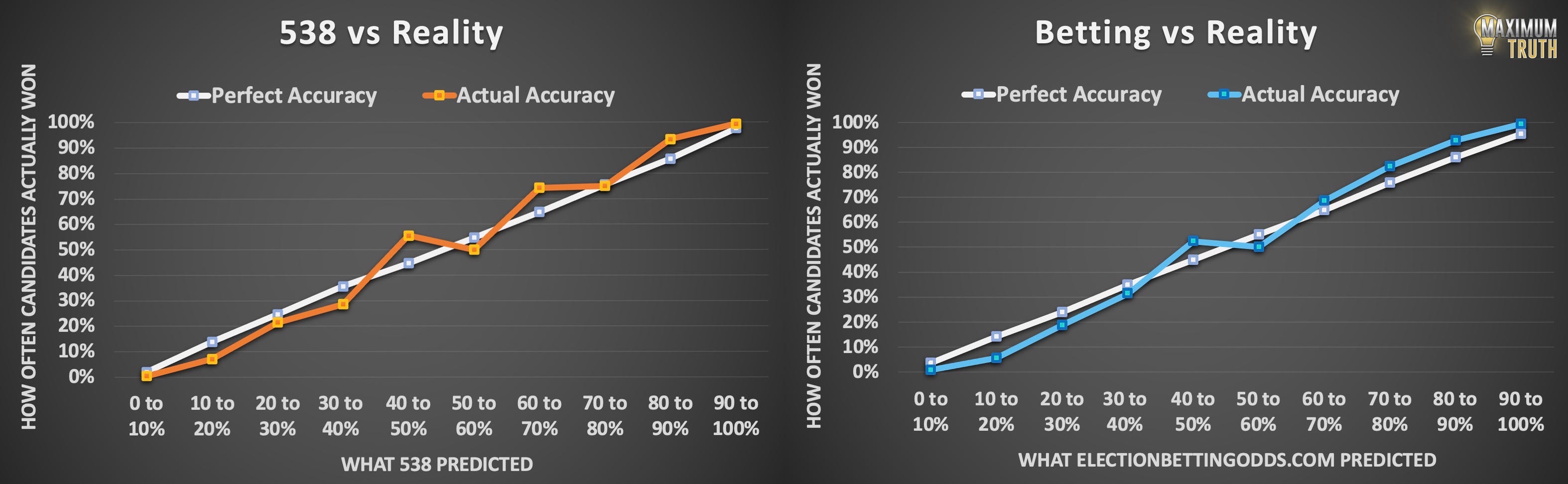
We can see that bettors’ prediction accuracy is not quite as good in this subset of the data. The races missing from this apples-to-apples dataset are foreign elections, special elections, and a few state primaries, which FiveThirtyEight did not model.
Eyeballing these side-by-side graphs, it’s not at all obvious which site had better predictions overall.
We need a quantitative measure of which site performed better.
Fortunately, there’s a metric called a “Brier score” that sums up prediction accuracy, which follows this formula: ( [100% if a win, 0% if a loss] - [Prediction %] )^2
If you call every race incorrectly with 100% certainty, your score will be 1 (perfect inaccuracy.) If you flip a coin to predict everything, your Brier score will be 0.25. If every you call every race correctly with 100% certainty, your Brier score will be 0 (the best possible score.)
So lower is better. It can be thought of as an “error score.”
Now that we have a measure, how do the sites compare?
Going into the 2022 elections (so, 2016-2020) ElectionBettingOdds.com had a very slight edge. Here are the Brier error scores, shown graphically:

Unfortunately, the bettors did not have a great year in 2022.
With 2022 added, FiveThirtyEight.com took a narrow lead:

It’s striking how similarly accurate the sites are, even though they often make quite different predictions. On a scale of “perfect” to “coin toss” their difference is barely visible.
Where bettors and 538 differed
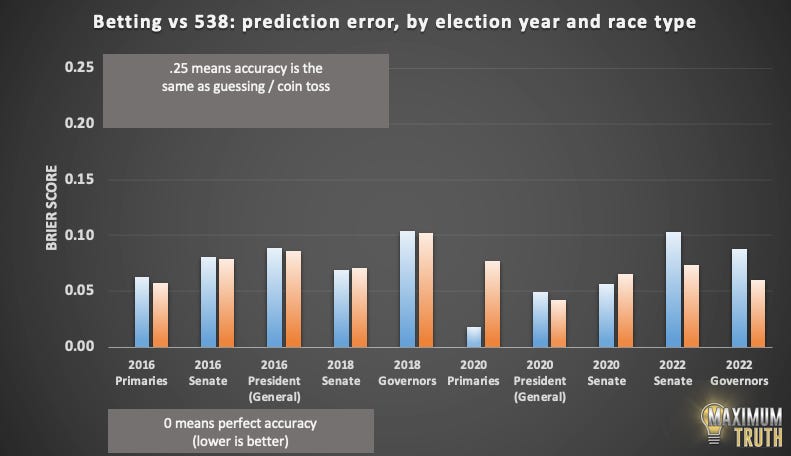
We can break down performance by election year. Lower bars are better:

2020 was the best year for bettors, and was the one election cycle in which they clearly outperformed FiveThirtyEight’s models.
Nate Silver generally knows the value of markets, but ironically, 2020 was the cycle in which he was most antagonistic towards them, tweeting that “prediction markets are basically competitive mansplaining” and, less jokingly, “political betting markets are populated by people with a sophomoric knowledge of politics.”
Bettors outperformed Silver in 2020. The clearest example was in Florida, where bettors gave Trump a 59.7% chance of winning the state, while Silver gave Trump only a 30.9% chance. Trump won.
But bettors got their turn to be relatively wrong in 2022, as they were broadly overconfident in Republican wins compared to Silver’s estimates. For example, bettors gave Republicans a 65.6% chance of winning, whereas Silver put it as a coin toss (51% for the Republican.) The Republican lost.
That got me wondering:
Do bettors generally overestimate Republicans, while 538 overestimates Democrats?
I ran the numbers:
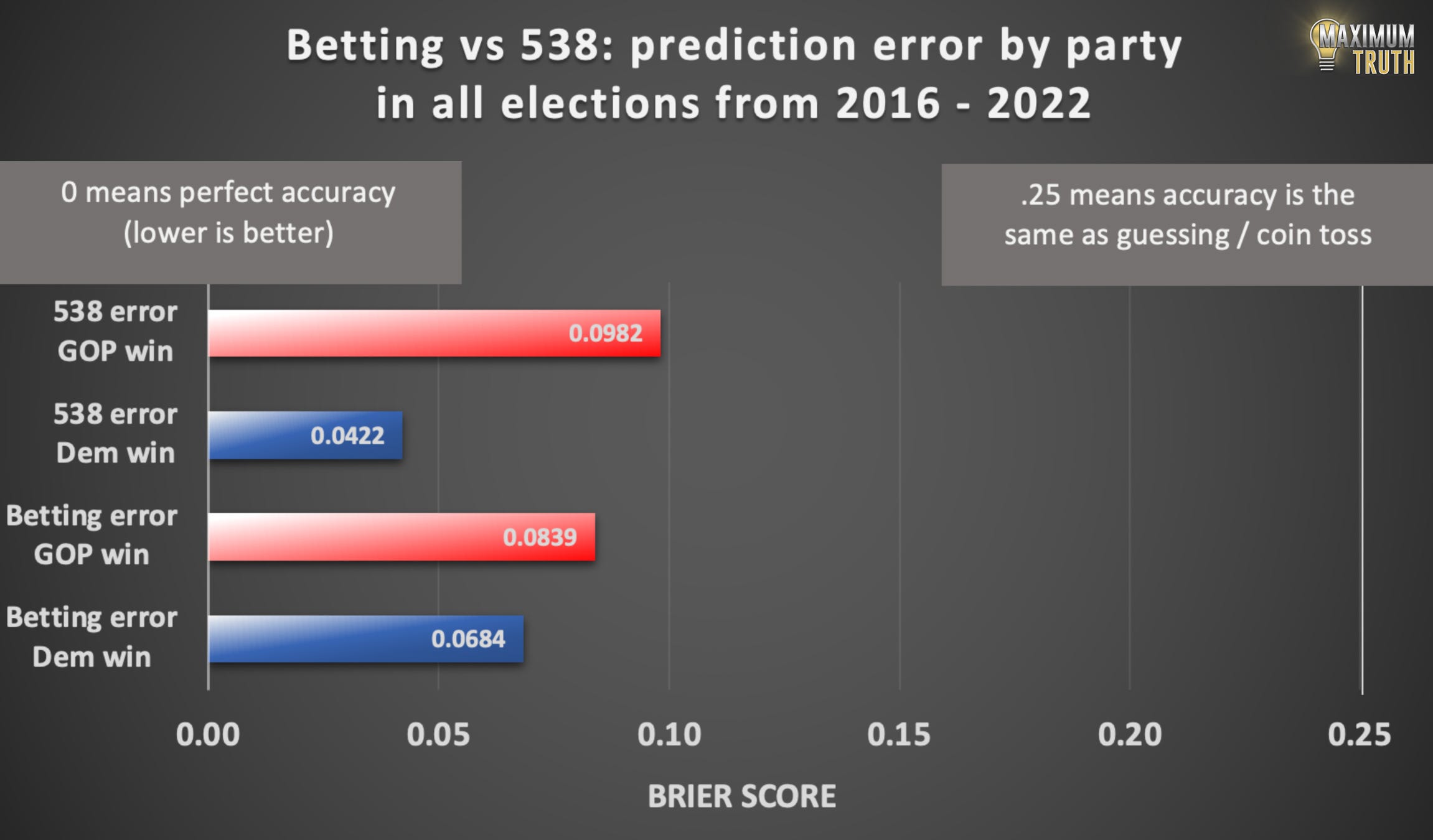
Fascinating.
So FiveThirtyEight’s predictions do have a bias towards Democrats. Specifically, their Brier error score was more than twice as high when Republicans won, indicating that their model was much more surprised by Republican wins.
Bettors also had some bias towards Democrats, but it was smaller. Compared to FiveThirtyEight, bettors were less surprised by Republican wins, and more surprised by Democratic ones.
But overall, FiveThirtyEight had less error than bettors (.0702 vs .0761) in this sample, which is slightly different from the earlier ones because it doesn’t include primaries, since everyone is of the same party in those.
Did accuracy vary by type of election?
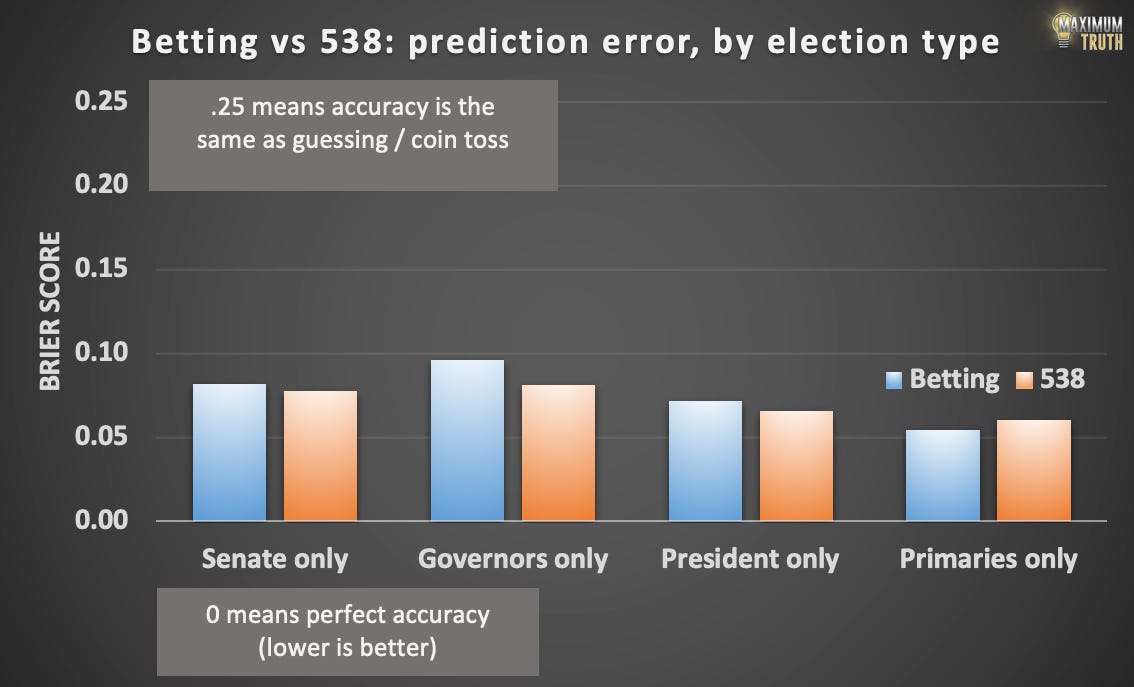
Betting performed the best in predicting primary outcomes, which are perhaps harder to model and require more subjectivity.
FiveThirtyEight’s most-wrong prediction was for Bernie Sanders in the Michigan 2016 primary; according to their data, they gave Sanders a .0001 chance of winning, or one in ten thousand. The bettors gave Sanders an 8.4% chance. Sanders won.
But to repeat, for fairness, FiveThirtyEight still had a slight edge in the races that both sites tracked.
Added, Dec 6, 2022: Here’s a chart with a full breakdown that’s both by year, and by type:
Can we do still better? Taking the average
A preprint study by Columbia and USC researchers compared PredictIt election bettors and The Economist’s election model in a narrow selection of 8 senate races in 2020. They found that taking the average of those two forecasts was better than either one.
Inspired by that, I looked at the same thing here.
And yes, the average performed better!

We see this averaging principle work in other areas, too.
The average of polls is a more reliable predictor than any one poll.
The average of betting markets is better than any one betting market.
And, apparently, averaging those two averages together also improves accuracy!
Similarity to stock markets
The above is reminiscent of the stock market’s efficiency, where a few investment managers do consistently beat the market over time — but most flame out and shut down, or chug along with slightly sub-par returns and complacent investors.
Betting markets are less efficient than the stock market, but there is real money involved: Over $400 million was bet on the 2020 election, and a couple million were bet on the 2022 election.
By the same token, Silver does a good job, but if there were stock-market level money at stake, there’d be dozens of companies trying to do what he does even better, with bots that trade in milliseconds, etc.
Conclusions
— For predicting elections, markets are virtually tied with the best statistical modeler (Nate Silver’s FiveThirtyEight.com.)
— Betting odds slightly outperformed 538 in accuracy for the period 2016 - 2020. However, in 2022, the betting odds did less well, and 538 now holds a narrow lead.
— Keep in mind that “underdog” bias exists in both ElectionBettingOdds.com’s and FiveThirtyEight’s predictions.
— Nate Silver’s site is worse than bettors at predicting Republican wins, and better at predicting Democratic wins.
— Taking the average of ElectionBettingOdds.com and FiveThirtyEight.com is more accurate than looking at either one individually.
— Ultimately, these are all fine-haired differences, and you’ll do well looking at either site, or both! Just don’t listen to some self-styled “expert” on a podcast, the Princeton Election Consortium, or ancient Assyrian clay tablets.
So that anyone can check my data, I’ve uploaded an Excel sheet with my dataset and graphs. You can download it here. Let me know if you see any issues!
Careful readers might notice that the graph is not perfectly symmetrical. For example, the 60-70% bucket is off somewhat, which is not reflected in the 30-40% bucket. This is because some races (in particular presidential primaries) have more than two candidates. In such a race, one candidate might have, say, 60%, which two other candidates each splitting a 20% chance.
Excellent article. I kind of love that bettors can perform as well as a professional in the business of statistics. I'll probably be checking out both sites for some electoral news soon, so thank you for writing this!
This is a very interesting article. A questions.
(1) With respect to your first chart ("Bettors vs. Reality"), do you have the R-square value? My statistics days are way behind me, but I think that is the goodness of fit measure -- please let me know if that's wrong. Just eyeballing the scatterplot, the R-squared value looks extremely high to me. Also (and this question may not make sense statistically), do you have the R-squared value just for the 20%-80% range where the predictions are most accurate?
(2) Intuitively, the Brier Score makes sense to me (I didn't work through the math), but does it vary much from just comparing the R-squared scores to one another? For your second panel ("538 vs. Reality" and "Bettors vs. Reality," do you have the R-squared scores for the two regressions? And do you have the R-squared scores for each? And the R-squared scores in the 20%-80% range for each?
(3) I'm usually particularly interested in the very close races. Do you happen to have a comparison of the bettors and 538 in those races, say in the 45% to 55% range or some similar mid-range?
Thanks for doing all this work. I find it fascinating.